据传言,Nvidia 预计要到 2027 年的“Rubin Ultra” GPU 计算引擎才会为其 GPU 内存绑定 NVLink 协议提供光学互连。这意味着每个设计加速器的人——尤其是超大规模和云构建者内部设计的加速器——都希望通过在 Big Green 之前部署光学互连来在 AI 计算方面胜过 Nvidia,从而获得优势。
由于加速器到加速器和加速器到内存的带宽瓶颈巨大,因此对光互连的需求如此之高,以至于筹集风险投资资金不成问题。我们看到这方面的行动越来越多,今天我们将讨论 Xscape Photonics,这是一家从哥伦比亚大学的研究机构分离出来的光互连初创公司。
无论你是否知道,哥伦比亚大学都是互连和光子学的温床。
Al Gara 教授和 Norman Christ 教授构建了一台采用 DSP 驱动的超级计算机,该计算机具有专有互连功能,可运行量子色动力学应用程序,并于 1998 年荣获戈登贝尔奖。这项 QCDSP 系统研究为 IBM 的 BlueGene 大规模并行超级计算机奠定了基础,Gara 是该超级计算机的首席架构师。(Gara 转投英特尔,也是其假定继任者——阿贡国家实验室的“Aurora”超级计算机的架构师。)
哥伦比亚大学有一组完全不同的研究人员致力于硅光子学研究,他们中的许多人联手创建了 Xscape Photonics。该公司联合创始人之一、光波研究实验室负责人 Keren Bergman一直在利用光子学降低系统中数据传输的能量。联合创始人 Alex Gaeta 是这家初创公司的总裁,他最初担任首席执行官,在量子和非线性光子学方面做了基础性工作,即参量放大器和光频梳发生器。联合创始人 Michal Lipson 发明了一些关键的光子学元件,例如微环调制器和纳米锥耦合器。联合创始人 Yoshi Okawachi 是光频梳这一特殊激光器的专家。
有趣的是,当这些哥伦比亚大学的研究人员决定将他们的光互连理念商业化时,他们选择了 Xscape 的联合创始人之一、并非来自哥伦比亚大学的维韦克·拉古纳坦 (Vivek Raghunathan) 担任首席执行官,因为加埃塔 (Gaeta) 决定减少自己的职责,重返大学教授职位。
Raghunathan 来自麻省理工学院,在那里获得了材料科学与工程学位,Xscape 的一些同事也曾在此工作过;他在麻省理工学院担任了六年的研究助理,参与了各种硅光子学项目,并于 2013 年加入英特尔,担任亚利桑那州钱德勒代工厂的高级封装研发工程师。Raghunathan 一步步晋升,领导开发了英特尔首款 100 Gb/秒以太网光收发器,并致力于其 GPU 到 HBM 互连。Raghunathan 曾在 Rockley Photonics 担任工程师,然后于 2019 年加入博通,担任“Humbolt”共封装光学器件的负责人,该器件用于 25.6 Tb/秒的 Tomahawk 4 交换机 ASIC 变体,由腾讯和字节跳动在中国部署。Raghunathan 启动了 52.6 Tb/秒 Tomahawk 5 代“Bailly”后续 CPO 项目,但在完成之前离开并加入了 Xscape。
本周的重磅新闻是,Xscape 在 A 轮风险投资中筹集了 4400 万美元,此前该公司于 2022 年成立后进行了 1300 万美元的种子轮融资。此次融资由 IAG Capital Partners 领投。有趣的是,HyperWorks 计算机辅助工程工具的创造者 Altair 是投资者之一,其创始人之一也是哥伦比亚大学的校友,也是工程学院的董事会成员。思科投资、Fathom Fund、Kyra Ventures、LifeX Ventures、Nvidia 和 Osage University Partners 也参与了投资。
Nvidia 的投资很有意思,因为需要将大量的 GPU 连接在一起,而这家 GPU 巨头在 3 月份宣布使用“Blackwell”B100 GPU 加速器推出的 GB200 NVL72 机架式系统中使用铜基 NVLink-NVSwitch 互连能够做到这一点。通过在 GPU 及其内存之间使用光导管,Nvidia 可以将数据中心真正变成一个巨大的虚拟 GPU。你可以打赌,这正是 Nvidia 想要做的事情,并且早在 2022 年,它就暗示了其带有 CPO 概念设计的 NVSwitch。
无论人工智能加速器的架构如何,它的问题在于,一旦超出给定设备的边缘,计算元素或内存之间的带宽就会开始逐渐减小,而且速度相当快。
对于任何加速器来说,都需要使用电信号将 HBM堆叠内存放置在非常靠近计算引擎的位置,这意味着你只能在芯片给定的周长内封装这么多东西。(并且你只能将内存堆叠得这么高才能增加容量,即使这样做,也不会增加带宽。只有更快的内存和更多的内存端口才能增加带宽。而且由于 HBM 价格昂贵且供应不足,我们看到 GPU 加速器路线图做了一些奇怪的事情,以匹配有限的内存容量和带宽,以应对有时性能过强的 GPU。
Raghunathan 说,归根结底,就是数据从加速器中出来的“逃逸速度”,这也是 Xscape Photonics 这个名字的由来。(不要太拘泥于字面意思。)

这些是我们经常谈论的数字,但最好将它们全部放在一个地方以显示逐渐减小的情况,当您查看 Nvidia GB200 混合集群时,该逐渐减小大约为 160 倍,每个“Grace”CG100 Arm 服务器 CPU 都有两个“Blackwell”GB100 GPU 加速器。带宽逐渐减小是将其中一个 GPU 与 400 Gb/秒 Quantum 2 InfiniBand 端口进行比较,该端口通常用于让 GPU 与集群中及其自身节点之外的其他 GPU 进行通信。
那么带宽减少会产生什么影响呢?这意味着数据无法足够快地进出 GPU。这会导致非常昂贵的设备的利用率低。
对于 AI 训练和推理,Raghunathan 引用了 Alexis Bjorlin 的数据,他曾经负责 Meta Platforms 的基础设施,但现在已转任 Nvidia 的 DGX Cloud 总经理。请看:
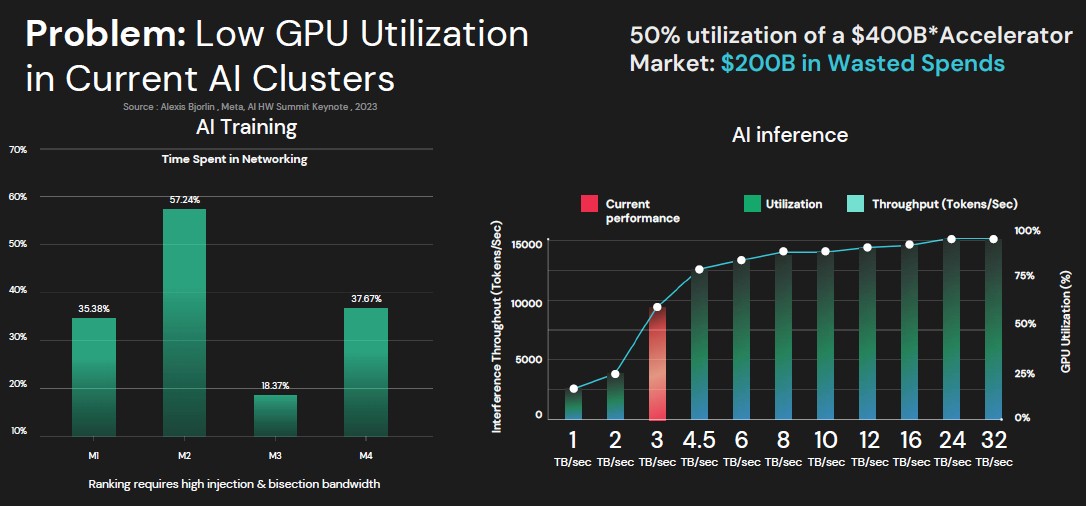
Raghunathan 告诉The Next Platform :“因此,对于训练来说,随着 GPU 的不断扩展,问题已经从 GPU 设备级性能转变为系统级网络问题。根据工作负载,你最终会花费大量时间在 GPU 之间的通信上。在 Meta 展示的图表中,他们讨论了某些工作负载,其中几乎 60% 的时间都花在了网络上。同样,当你考虑推理时,你会看到最先进的 GPU 在进行 ChatGPT 搜索时利用率在 30% 到 40% 之间。这种低 GPU 利用率是我们的客户想要解决的根本问题,因为他们会继续购买数十亿美元的 GPU。”
这个数学很简单。利用率为 50% 时,峰值计算的百分比是由有限的 GPU 进出带宽预先决定和限制的,这意味着 GPU 的成本是你认为的两倍,这意味着你浪费了一半的钱。
现在,公平地说,我们非常怀疑全世界的平均 CPU 利用率是否会高于 50%。但平均 CPU 成本也不会达到 30,000 美元。每年大约 1500 万台服务器的平均成本可能接近 1,000 美元。但这仍然是每年数百亿美元的低效浪费。GPU 的浪费比“损失”的资金多出一个数量级,这就是每个人都感到恐慌的原因。
“我们真正想在 Xscape Photonics 解决的就是带宽逐渐减少的问题,”Raghunathan 说道,他与我们听到的Ayar Labs、Lightmatter、Eliyan、Celestial AI 、 Ultra Accelerator Link 联盟成员等许多公司的意见一致。“我们如何解决这个问题?我们认为,将所有从 GPU 中逸出的电信号直接转换为同一封装中的光信号,并在我们将 GPU 和内存池连接在一起时最大化利用光信号,这是扩展 GPU 性能最具成本效益和能源效率的方法。”
Xscape 团队想出的诀窍是,使用一种激光器,它可以同时从光纤中驱动多种波长,比如多达 128 种不同的颜色,这意味着带宽可能比驱动四种不同颜色的光互连中使用的激光器高 32 倍。此外,Raghunathan 表示,Xscape 的 ChromX 平台方法将使用更简单的调制方案,如 NRZ,它不会像 PAM-4 等高阶调制方案那样影响延迟,近年来,这种方案已用于提高 InfiniBand 和以太网的带宽。
或许同样重要的是,ChromX 光子平台是可编程的,因此提供的波长数量与特定 AI 训练或推理工作负载的需求以及加速器与其 HBM 内存之间的连接需求相匹配,所有这些都在交换结构基础设施内完成。可编程激光器将率先问世,其概念如下:
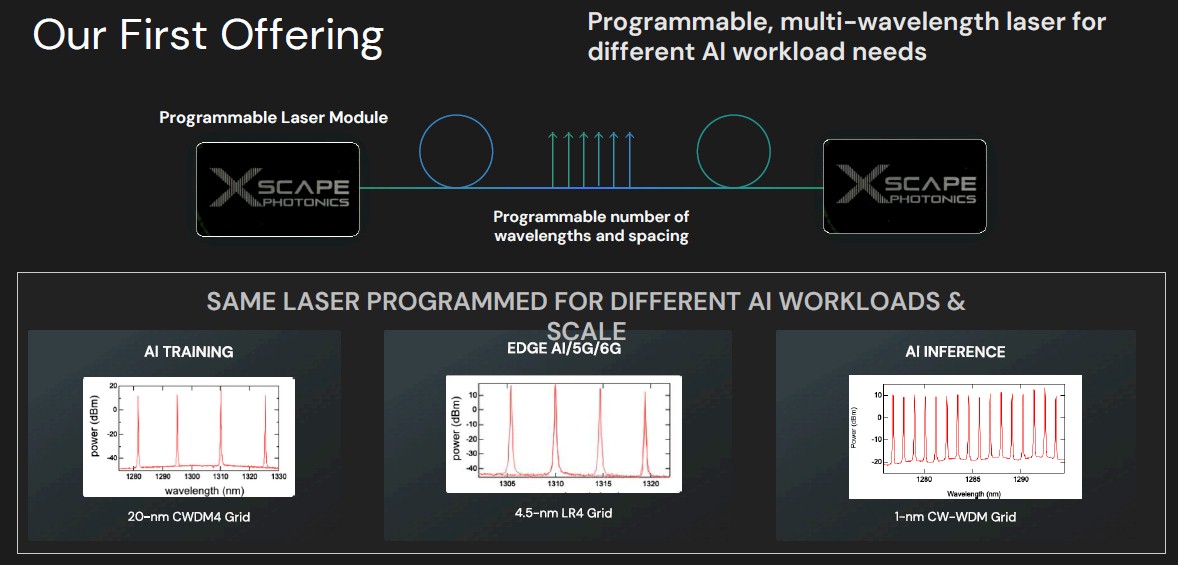
该图表左侧显示了 CWDM4 收发器用于创建 AI 训练集群互连的激光器所需的四种波长。
中间是制造 LR4 光纤收发器所需的四种不同波长,这种光纤收发器通常用于当您必须使用光纤链路跨越两个数据中心并同步链接它们时,以便可以在两个数据中心上进行训练,就好像它们是一个更大的数据中心一样。
右边是一个推理引擎,它有一个交换加速器和 HBM 内存复合体,与 Nvidia 对 NVLink 和 NVSwitch 所做的有很大不同,并且有 16 种不同的波长。
不同的波长对应于设备之间的预期距离。根据 Raghunathan 的说法,设备之间的训练距离通常为 2 公里或更短,跨数据中心边缘用例预计在 20 公里到 40 公里之间,但有些人说的是 10 公里到 20 公里。推理具有更多波长,设备之间的距离预计在 10 米到 200 米之间,并且需要更多的带宽才能使这些设备高效运行。
后一点与计算和内存的分解结构架构有关,我们认为这对于训练和推理都有效,这很有趣。让我们来看看:
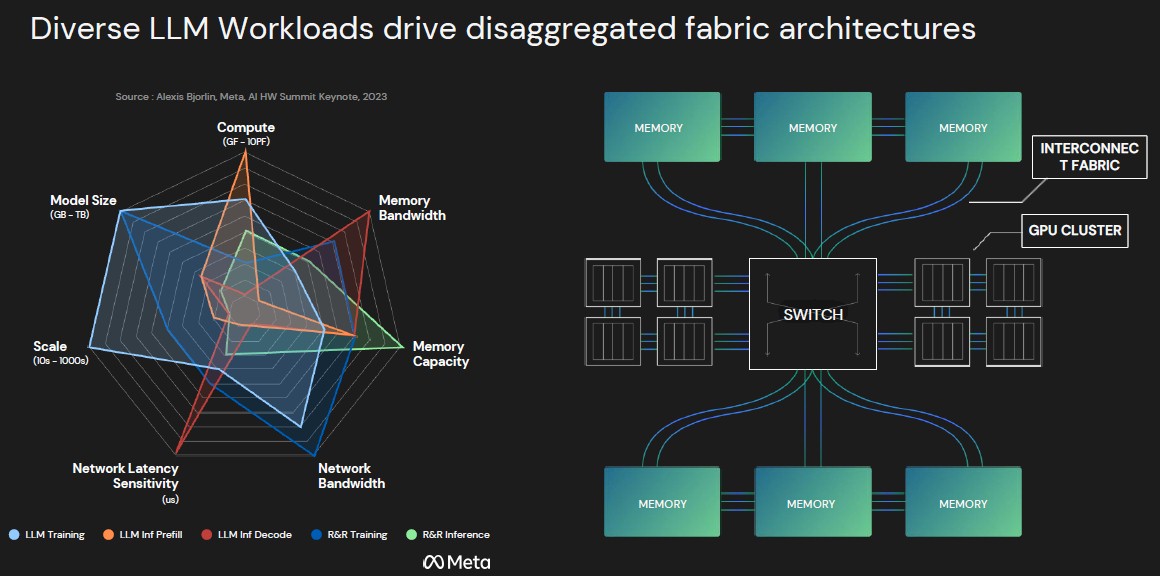
这种架构下,HBM 内存不连接到 GPU,而是粘合在一起,这些存储体可能位于机架中物理上不同的架子上,或跨整个机架。GPU(或任何类型的 AI 或 HPC 加速器)都存储在一起,因此它们可以在一致性域中共享缓存中的本地数据,但它们都通过交换机连接,该交换机将加速器池与内存池交叉连接。上述每条管道都是一条光链路,其属性可以由 ChromX 平台编程,使用适当数量的波长和适当的频率来满足带宽和距离(以及延迟)要求。
“我们的技术几乎打破了成本障碍和规模障碍,并且非常可靠,因为我们只需要一个激光器就可以泵送一块硅片,而且我们可以从单个设备生成多达数百个波长,”Raghunathan 说。“我们提供了一个全新的带宽扩展向量。核心 IP 由哥伦比亚大学独家授权,完全归我们所有。我们的愿景是将封装内通信带宽与封装外通信逃逸带宽相匹配。我们认为,当我们使用多色方法时,我们可以匹配这一点,以便大型数据中心(或多个数据中心)可以像一个大型 GPU 一样运行。”
目前,Xscape Photonics 并未试图制造支持这种分解式光子结构的网络接口或交换机,而是试图制造其他人想要购买的适合的低功率、多色激光器,以制造这些设备。他们拥有一台激光器,可以实现所有这些频率,而市场上其他人则必须使用多台激光器来实现这一点。他们的想法是将加速器及其内存的互连总功耗降低 10 倍,同时将带宽提高 10 倍,从而将每个带宽的能量降低 100 倍。
看看谁会采用这款 Xscape 激光以及如何采用它,将会很有趣。