In recent years, large language models (LLMs) have achieved breakthroughs in language understanding, generation, and generalization, becoming indispensable for text-based tasks. As research progresses, attention has shifted toward extending these capabilities beyond text to other modalities such as images, audio, video, graphs, and recommendation systems. This unified multimodal modeling brings new opportunities but also poses a critical challenge: how to transform diverse signals into discrete representations that LLMs can process.
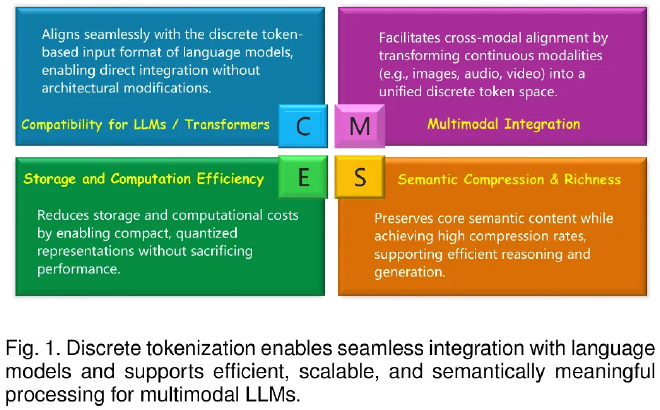
Against this backdrop, Discrete Tokenization has emerged as a key solution. Techniques such as Vector Quantization (VQ) convert high-dimensional continuous inputs into compact discrete tokens. These tokens not only enable efficient storage and computation but also align seamlessly with the native token mechanism of LLMs—unlocking stronger cross-modal understanding, reasoning, and generation.
Despite its growing importance, research on discrete tokenization for multimodal LLMs has lacked a systematic review. To address this, a research team has released the first comprehensive survey, mapping the technical landscape, practical applications, open challenges, and emerging directions. This review serves as a technical roadmap for the field.
Method Landscape: Eight Core Approaches #
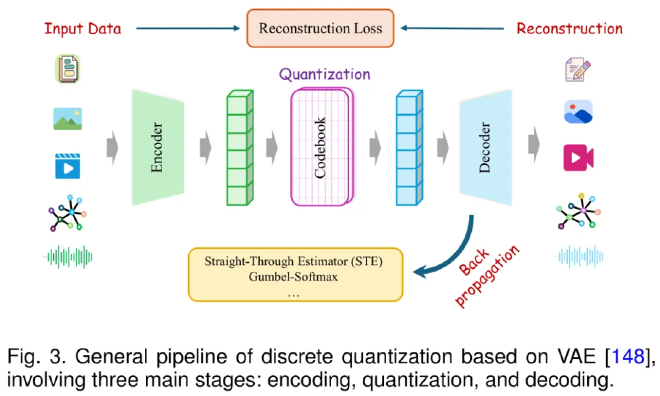
The review systematically categorizes eight major vector quantization methods, from classical approaches to cutting-edge variants, highlighting differences in codebook construction, gradient propagation, and quantization implementation:
- VQ (Vector Quantization): Classical codebook design and update, simple and easy to implement.
- RVQ (Residual Vector Quantization): Multi-stage residual quantization for progressive precision.
- PQ (Product Quantization): Subspace partitioning with independent quantization.
- AQ (Additive Quantization): Multiple codebooks stacked to enhance representational power.
- FSQ (Finite Scalar Quantization): Dimension-wise mapping to finite scalar sets with implicit codebooks, avoiding large storage overhead.
- LFQ (Lookup-Free Quantization): Direct discretization via sign functions, eliminating explicit codebooks.
- BSQ (Binary Spherical Quantization): Discretization on the unit sphere using binary representations.
- Graph Anchor-Relation Tokenization: Specialized for graphs, anchoring nodes and relations to reduce cost.
Each method has unique strengths across training stability, gradient handling, and quantization accuracy, making them suitable for different modalities and tasks.
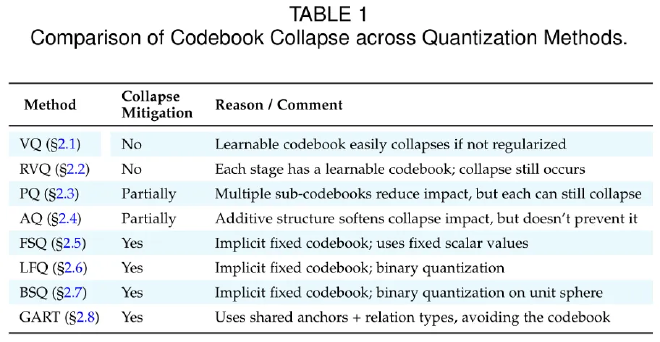
A Core Challenge: Codebook Collapse #
A recurring issue in practice is codebook collapse, where most entries in the codebook converge to a few vectors, reducing diversity and limiting expressiveness.
Common mitigation strategies include:
- Code Reset: Re-initializing rarely used codes near active ones.
- Linear Reparameterization: Optimizing code distribution and keeping inactive codes learnable.
- Soft Quantization: Representing inputs as weighted combinations of multiple codes.
- Regularization: Using entropy or KL-based constraints to encourage balanced usage.
Solving codebook collapse is essential for improving the stability and generalization of discrete tokenization in multimodal LLMs.
Early Applications: Before LLMs #
Even before LLMs, discrete tokenization was applied in both single-modality and multimodality tasks:
-
Single-modality:
- Images: Retrieval and synthesis, balancing global semantics with local details.
- Audio: Stable intermediate representations in codecs, balancing compression with quality.
- Video: Frame-level compact tokens for controllable generation and long-sequence modeling.
- Graphs & structured data: Mapping nodes, edges, and interactions into compact forms for representation learning and recommendations.
-
Multi-modality:
- Vision–Language: Visual features discretized into tokens, aligned with text tokens for captioning and retrieval.
- Speech–Text: Speech discretized into tokens aligned with text, enabling recognition, synthesis, and translation.
- Cross-modal generation: Tokens unify vision, audio, and text inputs for multimodal output generation.
These early applications laid the groundwork for discrete tokenization’s role in the LLM era.
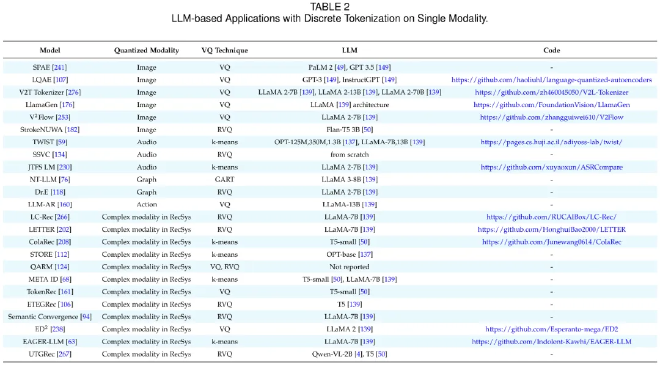
LLM-Driven Single-Modality Tokenization #
With LLMs as the backbone, discrete tokenization has been widely adopted for non-text modalities:
- Images: Tokens encode both local detail and global semantics, enabling captioning, editing, and generation.
- Audio: Quantized speech units support recognition and synthesis.
- Graphs: Nodes and edges discretized for classification, prediction, and graph learning.
- Motion sequences: Actions and control signals tokenized for sequence prediction and generation.
- Recommendation systems: User behaviors and item attributes mapped into tokens to improve ranking and personalization.
By bridging non-text data into the same token space as language, discrete tokenization allows LLMs to leverage their sequence modeling power across modalities.
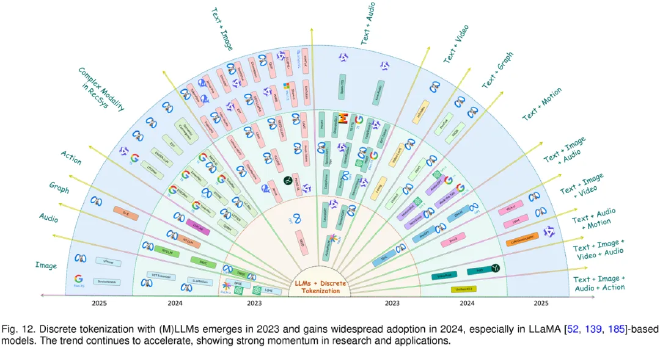
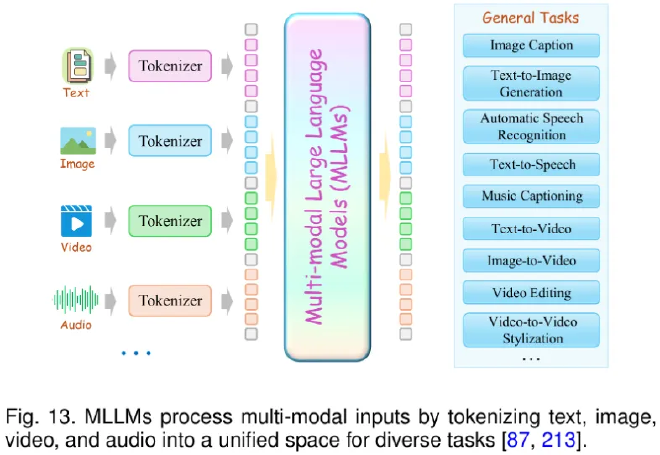
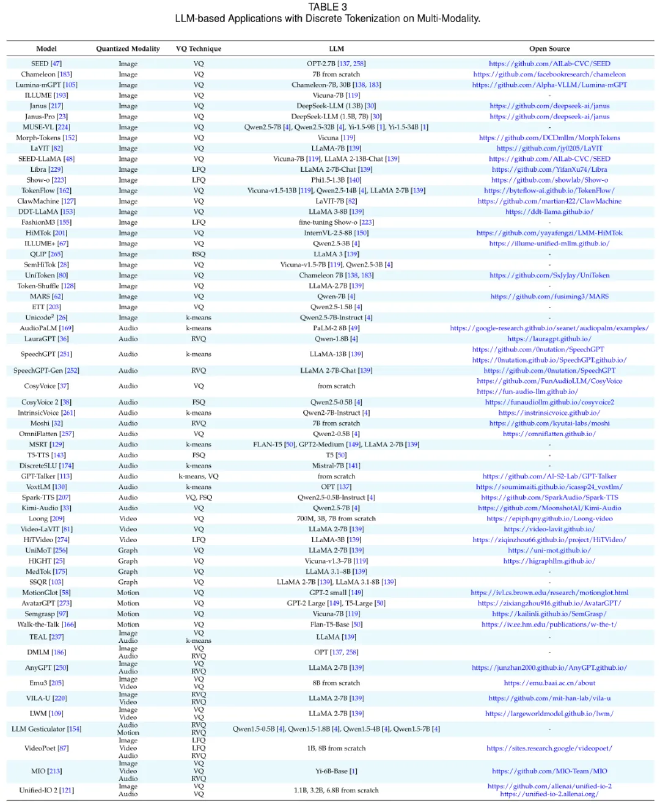
LLM-Driven Multimodal Tokenization #
In multimodal tasks, discrete tokenization plays an even more critical role: it establishes a shared semantic bridge across different modalities.
-
Bimodal Fusion (from 2023 onward):
- Text + Image (dominant)
- Text + Audio
- Text + Video
- Text + Graph
- Text + Motion
-
Multimodal Fusion (3+ modalities):
- Text + Image + Audio
- Text + Image + Video
- Text + Image + Audio + Motion
Through a unified token space, LLMs can handle complex tasks such as multimodal retrieval, question answering, synthesis, and dialogue without designing separate architectures for each modality.
Challenges and Future Directions #
While progress is significant, key challenges remain:
- Under-utilized codebooks and lack of diversity
- Semantic loss during quantization
- Gradient flow difficulties
- Granularity vs. semantic alignment trade-offs
- Lack of integration between discrete and continuous representations
- Limited cross-modal and cross-task transferability
- Poor interpretability and controllability of tokens
Future research may focus on adaptive quantization, unified frameworks, bio-inspired codebooks, cross-modal generalization, and improved interpretability.
Conclusion #
As the bridge between modalities and LLMs, discrete tokenization will only grow in importance as model capabilities expand.
This first systematic review offers a comprehensive technical map, spanning eight families of methods and their applications from single-modality to multimodal fusion. By organizing knowledge along modality lines, it not only traces the field’s evolution but also provides researchers with a structured reference for innovation and practical deployment—accelerating progress in multimodal AI.